
データマイニングが参考になるとき
ちょっと遡りますが、
2010年1月31日(日)中京1Rの上位人気単勝オッズです。
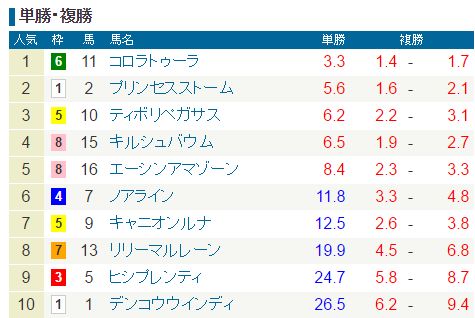
このレースは、オッズを見て分かる通り上位人気があまり信頼されていない牝馬限定戦です。
上位人気から軸馬を1頭選べと言われたら、かなり悩みます。
このようにオッズが割れている時に参考になるのがデータマイニングです。
データマイニングは、JRA-VAN NEXTに加入されている方が閲覧できる、あらゆるファクターを総合的に分析した指数です。
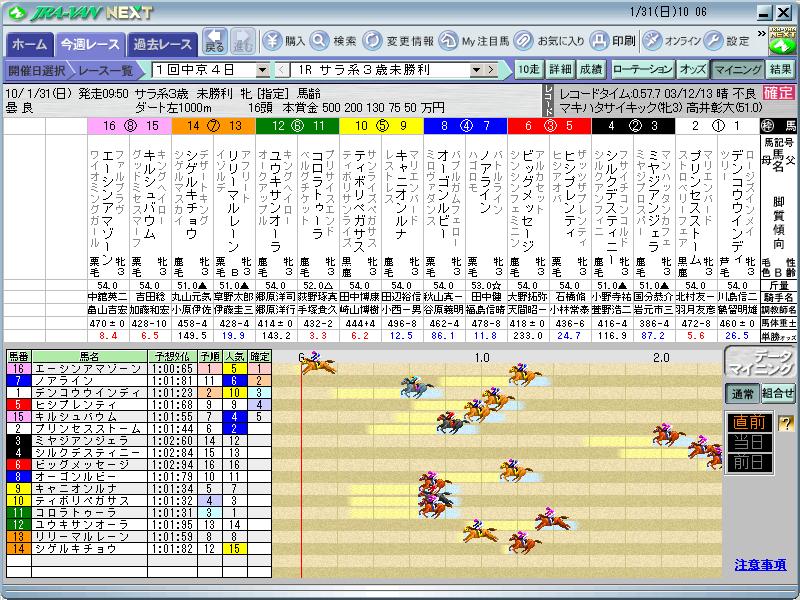
今回は、中京1Rのタイム型データマイニングを見てみます。
タイム型データマイニングは、各馬の走破タイムを予想します。
↓ ↓ ↓
注目してほしいのは
16番エーシンアマゾーンです。
単勝5番人気なのですが、データマイニングでは1位と予測され5番人気にもかかわらず大きく評価されています。
さらに予想タイムが1:00:65です。
2位の予想タイムが1:01:23です。
競馬では一般的に0.2秒=1馬身と計算されていますので、
予想タイムから考えると2位の馬に3馬身の差をつける予想しているのです。
短距離の1000mで3馬身差ですので、着差以上に強い競馬をしていることになります。
実際の結果はデータマイニングの予測通り
16番エーシンアマゾーン1着となりました。クビ差で勝ちはしましたが、
3連複配当は65,710円、3連単は335,090円と大きく荒れたレースとなりました。
ただし、毎回データマイニングを信頼していいわけではありません。
信頼してしまって裏切られることも多々あります。
今回のケースのようなオッズが大いに割れているときは、
軸馬を探す際の参考のひとつになることがあります。